knitr::include_graphics("pic/zetero-export-betterbib.png",error = F)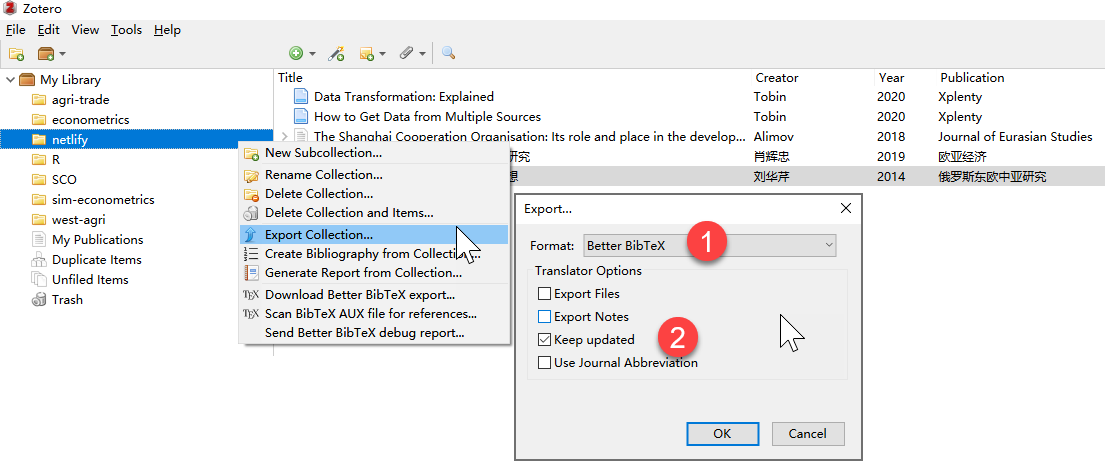
使用Rmarkdown写科学论文,自然避免不了管理和使用参考文献,以及文献输出样式。
很长一段时间异来,我的唯一文献工具是EndNote(版本X9)。掐指一算,差不多已经坚持使用了近13年了。多年来攒下的一个文献库.enl里,文献条目多达3500条(多半是存而不读的啦)。
在使用Rmarkdown写文章后,工作流程总是免不了受这个多年的工具牵连。可行的办法如下:
查找学术文献。利用谷歌学术查找文献,导入EndNote。(google学术设置里拉选一下默认导入工具)
修改定制EndNote软件。Endnote里一番神设置(具体见后),获得文献条目的BibTex格式。
集中注意力写文章的地方。Rmarkdown文档.Rmd里写文章,同时新建一个.bib的附带文件。
管理BibTex文献的地方。把BibTex格式的文献条目,复制到.bib文件里面去。
管理正文里文献引用显示和以及参考文献的输出样式。与.Rmd并行配置一个.csl文档。关于引用样式语言——Citation Style Language (CSL) ,后面再说。
目前的流程是没有可行的,但是几个问题仍旧存在:
EndNote重度使用的后遗症。一是要手动把EndNote文献条目的BibTeX内容复制到.bib里面去,太费手啦!二是,EndNote文献条目的BibTeX内容中,引用ID需要手动调整,这个也是很费手!
文献管理存档的主副之争。EndNote文献条目,跟.bib里的文献条目是无法关联的。意味着,要同时管理两个家伙!
引用样式语言Citation Style Language (CSL) 文档,可能需要定制化修改!
先不说这些血泪控诉的坑吧,下面把基本过程里的小九九暂时给记录下来。
步骤1:配置EndNote软件(Windows系统)。修改定制EndNote软件。具体可以参考攻略。
基本步骤大概是: - 下载style模板,导入并保存模板;然后选用此模板 - 修改Preferences : “modify reference types” - 修改display fields: “Custom1”
步骤2:EndNote里编辑条目。编辑文献条目。独立设置ID :BibTeX里编辑。
步骤3:定制输出和显示样式
准备好输出显示样式。cls样式可以参看样式库
设置.Rmd文档的yaml参数,示例如下:
# 一级yaml参数
biblio-style: "nnsfc.csl"
csl: "nnsfc.csl"
步骤4: 文献引用。直接使用条目的唯一标识。例如:
研究发现,balabalabala[@Birthal2011]。
Rmarkdown写作环境下,Zotero + rbbt的方式,基本上实现了比较满意的文献管理和引用流程。Zotero具有免费和相对开放性。Zotero对bibTeX和中文情景比较友好。此外,R包rbbt函数实现了对Zotero的实时联系,引用流程更加自动化。使用者需要正确理解Rmd渲染输出、.bib文件状态和Zotero条目库的关系。
安装文献管理软件zotero和浏览器插件 。官网
软件本体Zotero 5.0 for Windows 下载。
浏览器插件Zotero Connector chrome 浏览器插件下载。
安装Zotero扩展插件zotero-better-bibtex 开发者网站。zotero-better-bibtex-5.2.78.xpi 下载安装。
具体修改方法:
设定citekey形式:打开Zotero\(\Rightarrow\) 编辑\(\Rightarrow\) 首选项\(\Rightarrow\) Better Bibtex(插件菜单\(\Rightarrow\) Citation keys。
更新citekey值:Zotero\(\Rightarrow\) 选中文献条目\(\Rightarrow\)鼠标右键 \(\Rightarrow\) Better Bibtex\(\Rightarrow\) refresh Bibtex key。
一种常见工作模式是,个人会在多设备下使用zotero。这时,就需要处理多个设备下,zotero全文附件的同步问题。
当然,zotero官方本身是支持这一点的。但是对于免费用户,仅仅300M的网络共享空间是完全不够用的,如果要更大网络共享空间,则需要掏钱购买,费用也是不低(尤其对于学生党而言)。
因此,为避开官方的收费方案,下面简要介绍如何搭建一个免费的、无限容量的、自动化zotero附件同步的工作流(参看)。
准备同步工具:google云盘备份同步工具(国内VPN、google账号)
准备zotero插件: 出了前述的插件外,还需要安装一个神奇插件ZotFile(下载地址)。
设定zotero参数:具体细节请参看。
以上准备和设定都完成后,实际个人多设备使用工作流程其实很简单:
在A设备上:保持google备份同步工具开启和正常联网,同时如常利用zotero进行文献收集、阅读和笔记记录。
在B设备上:保持google备份同步工具开启和正常联网,zotero则会自动同步全部文献条目和全文附件(pdf)。
注意:(1)只需要对全文附件进行云同步,例如”D:-local“,里面含有zotofile管理的全部全文附件文件。(2)不要对”D:-store”文件夹进行云端软件(例如google drive)同步,这是zotero软件系统文件,里面含有
.sqlite或.json文件等,都是zotero软件实时文件,因此不应该进行云同步。
步骤1:zotero导出.bib文件。选定需要的Zotero的文献组(group),以Better BibTeX格式(前提是要安装相应插件)导出到工作路径"netlify/content/bib/netlify.bib",注意同时要勾选“keep updated”选项。这样的话就能实现Zotero文献的自动关联。
knitr::include_graphics("pic/zetero-export-betterbib.png",error = F)
步骤2:写作文件.Rmd的yaml区域指明对.bib的关联关系,并设定文献列出样式(csl style)及关联关系(参看“文献管理:CSL风格样式”一文)。
bibliography: "../../bib/netlify.bib"
csl: "../../bib/china-national-standard-gb-t-7714-2015-author-date.csl"
link-citations: yesrbbt调用文献# remotes::install_github("paleolimbot/rbbt")
require("rbbt")R包rbbt的主要作用见github:
与Zotero文献库直接关联,方便引用。
与.Rmd文件头yaml区域指定的.bib文件关联,实现“参考文献”列出。
主要过程:
rbbt包。# remotes::install_github("paleolimbot/rbbt")
require("rbbt")很多时候,我们更希望直接看到指定预览格式的文献条目细节,或者希望直接快速地将预览格式的文献条目复制粘贴到word、Rmarkdown或txt里去。
下面是实现操作(参看 指导说明):
设置指定预览格式。edit \(\Rightarrow\) preference \(\Rightarrow\) export。
选中文献条目,直接用鼠标拉到你想要放置的地方去。
具体可以参看的Rmarkdown官方解释。
[@refkey1; @refkey2]一些国内学者[@liuhuaqin2014; @xiaohuizhong2019]一起发现...。[-@refkey]有学者[@alimov2018 pg 11]...发现。他还发现[-@alimov2018]...。有学者(Alimov 2018 pg 11)…发现。他还发现(2018)…。
@refkey says that ...@tobin2020a 认为...。Tobin (2020) 认为…。
经验法则:对于问题1,选好CSL模板很重要。对于问题2,建议保留原始分隔符号(圆点),后面在输出的word中可以批量将
\cdot替换为原始分隔符号。
Zotero官方列出了很多CSL样式,其中有一些可以作为参照的中文样式(参看):
China National Standard GB/T 7714-2015 (author-date, 中文)
China National Standard GB/T 7714-2015 (numeric, 中文)
National Natural Science Foundation of China (numeric, 中文)
考虑到实际使用的有效性,我基于china-national-standard-gb-t-7714-2015-author-date.csl样式,做出了一些定制化的样式修改china-national-standard-gb-t-7714-2015-author-date-hhp.csl。具体可以参看和下载。
当然,也还是发现了部分问题,例如:
问题1:CSL中如何添加新的文献类型,例如新闻报道”Newspaper Article”。
引用形式为:(董峻 2020)。
但文献列表并没有按照如下格式呈现:
董峻,我国在应用核技术育种方面取得一批重要成果[N],新华网,2020-08-07,http://www.xinhuanet.com/tech/2020-08/07/c_1126340276.htm问题2:中文翻译的外国人姓名或少数民族姓名。
实际名字:阿卜杜拉•马达利耶夫
条目形式1:
Author: (last) 阿卜杜拉, (first)马达利耶夫
引用显示为:(阿卜杜拉马达利耶夫. 和 史 2011)
文献列表显示为:
阿卜杜拉马达利耶夫, 史谢虹,. 乌兹别克斯坦创新科技发展状况[J]. 俄罗斯中亚东欧市场, 2011(02): 16–17.条目形式2:
Author: (last) 阿卜杜拉, (first)·马达利耶夫
引用显示为:(阿卜杜拉\cdot马达利耶夫. 和 史 2011)
文献列表显示为:
阿卜杜拉\cdot马达利耶夫, 史谢虹,. 乌兹别克斯坦创新科技发展状况[J]. 俄罗斯中亚东欧市场, 2011(02): 16–17.想要修改CSL样式(一般是微调),基本过程是:先获得想要的CSL样式,然后使用样式编辑器,预览文献条目,根据修改意图,按照CSL语言标准做出相应修改。具体来看,需要完成如下步骤:
步骤1:在线快速查找CSL样式,并简单预览基本风格。
打开网址Zotero Style Repository,在”style Search”框中搜索想要的样式。
将鼠标移到样式条目上1~2秒,就能看到基本的引用和文献预览风格。
步骤2:预览指定的文献条目的引用和文献风格。例如,有时候我们希望进一步看到特定文献类型(如Newspaper Article 或Webpage)文献条目的引用和文献风格。
调出样式编辑器”Zotero style Editor”。具体操作(Windows):打开Zotero桌面版 \(\Rightarrow\) 点击下拉菜单”Edit”,再点击”Perferences” \(\Rightarrow\) 点击”Cite”选项页,下面再点击”Style Editor”按钮。
选择、复制和粘贴目标样式文本。根据步骤1的操作,下载目标样式文件A.csl文件 \(\Rightarrow\) 使用Notepad++文本软件打开A.csl文件 \(\Rightarrow\) 复制全部文本 \(\Rightarrow\) 粘贴全部文本到上述已经调出的样式编辑器”Zotero style Editor”。
预览文献条目的引用和文献风格。在Zotero软件的文献库中选定文献条目 \(\Rightarrow\) 在”Zotero style Editor”中点击”Refresh”按钮,即可看到预览风格。
步骤3:小幅修改获得定制化的CSL样式。这个没有办法,只能根据相关文档来了解CSL语言,并掌握如何修改细节代码。相关CSL语言的介绍和说明文档包括:
参看一般性的说明。Primer — An Introduction to CSL。
参看手把手教你Zotero里修改。Editing CSL Styles - Step-by-Step Guide。
操作(官方):参看Find and edit CSL citation styles
操作(开发):参看CSL开发和检查CSL Style Development。
修改好后务必记得要保存并检查A-modified.CSL的语法规范性和完整性。使用在线检查器:“CSL Style and Locale Validator”网址。
一个在线资源,提供了Rmarkdown使用过程中的经验总结,很值得收藏查阅。RMarkdown for Scientists。
经验法则:多语言支持是目前csl语法中的一个重大挑战。中文出版环境下,csl体系和规范相对比较落伍,可维护性较差。
典型表现: - “et al.” (English) = “等.” (Chinese) - “nth edition” (English) = “第n版” (Chinese)
CSL关于多语言支持的长期讨论可参看:
参看初始讨论。proposal: allow locale-specific layouts
参看。Will csl support multiple languages/locates in one style?
国内人员做出的一些努力:
redleafnew在这里收集整理了国内常用的csl样式库。github 仓库
redleafnew在知乎上开设的专栏
知乎博文提到了Jurism与Zotero的关系。
中文姓氏合并/拆分的插件工具。Jasminum - 茉莉花仓库。
若干问题:
(1)目前,不论使用各种声称解决了”.et al”和”等”的csl样式,结果都会出现“按下葫芦起了瓢”的各种新问题。但是奇怪的是,同样的csl样式,在zotero里预览是正确的,但是在Rmarkdown 渲染后就出现各种状况。
例如,重复出现citation和bib的情况:
(Acharya, A. et al., 2016Acharya et al., 2016)这篇外文文献有三位作者。
(Brown, C. et al., 2021Brown et al., 2021)这篇外文文献有五位作者。
这篇中文文献有三位作者(祝继高. et al., 2021祝 et al., 2021)。
这篇中文文献有五位作者(朱晶. et al., 2021朱 et al., 2021)。
[13] 祝继高, 王谊, 汤谷良. 《一带一路》倡议下的对外投资:研究述评与展望 [J]. 外国经济与管理, 2021, 43(3) : 119–134[13] 祝继高, 王谊, 汤谷良. 《一带一路》倡议下的对外投资:研究述评与展望[J]. 外国经济与管理, 2021, 43(3) : 119–134.
[14] 朱晶, 张瑞, 张瑞华, 等. 新冠肺炎疫情下进口限制措施对农业贸易的影响与思考 [J]. 世界农业, 2021, (5) : 4–15+126[14] 朱晶, 张瑞, 张瑞华, 等. 新冠肺炎疫情下进口限制措施对农业贸易的影响与思考[J]. 世界农业, 2021, (5) : 4–15+126.Rmarkdown 基于pandoc,而pandoc的文献引用则基于citeproc
padoc之前的文献引用是基于 pandoc-citeproc(已经弃用)
截至目前,都是基于version 1.0.2 of the CSL spec。但是CSL标准的1.1版本期望会有大变动(更好支持多语言)
具体查看的R代码如下(参看):
rmarkdown::find_pandoc()$version
[1] '3.1.11'
$dir
[1] "C:/Program Files/RStudio/resources/app/bin/quarto/bin/tools"rmarkdown::pandoc_citeproc_args()[1] "--citeproc"经验法则:a.规范情形下应该正文引用和文献列表一一对应,而不应该取巧或不规范。b.下列两种情形都应该归为“不规范”使用,但是有时候却比较实用。
参看资料:yihui/rmarkdown-cookbook:4.5 Bibliographies and citation。
情形1:不在正文正式引用,但是希望在“参考文献”中列出。
---
nocite: |
@item1, @item2
---情形2:把bib库中的所有文献条目全部列出在“参考文献”中,不管正文是否正式引用。
---
nocite: '@*'
---默认情况下,文献列表会出现在整个文档的最后。
如果要指定其出现位置,则需要插入一小段html代码<div id="refs"></div>,具体如下(可参看)。
# Introduction
# References {-}
<div id="refs"></div>
# Appendix
其中heading里面的{-}是为了保持不自动给出“索引id”。
如果使用了脚注功能1,脚注列表依旧会显示在文档最后。
此外,为了避免在每章的最后(默认的)和全书的最后(定制的)同时出现文献列表,还需要继续设置_output.yml:
bookdown::gitbook:
fig_caption: true
number_sections: true
css: css/text-box.css
split_by: chapter
split_bib: false一种方案,使用R包bib2df(参看cran)。
library("bib2df")
path_bib <- "bib/R.bib"
df_bib <- bib2df(path_bib) %>%
#as_tibble() %>%
janitor::clean_names()
DT::datatable(
df_bib,
options = list(dom = "tip",
pageLength =5,
scrollX=TRUE),
caption = "bibtex文件转tibble的一个演示")另一种方案,使用R包RefManageR以及bibtex(参看“A Roundup of R Tools for Handling BibTeX”博文链接)。
# other solutions
library("RefManageR")
library("bibtex")
path_bib <- "bib/bib.bib"
df_bib <- RefManageR::ReadBib(path_bib) %>%
as_tibble()
DT::datatable(
df_bib,
options = list(dom = "tip",
pageLength =5,
scrollX=TRUE),
caption = "bibtex文件转tibble的另一个演示")Rmarkdown写作环境下,Zotero + rbbt的方式,基本上实现了比较满意的文献管理和引用流程,优点如下:
Zotero的免费和相对开放性。免费+插件扩展。对很多网站的文章citation能够快速识别并导入到Zotero库里去,而且还能自动下载关联pdf!
Zotero对bibTeX的友好性。因为Rmarkdown对bibTeX的要求,而Zotero的相关操作极为便捷简单。此外,Zotero对中文文献情景也比较友好。
R包rbbt函数实现了对Zotero的实时联系,引用流程更加自动化。
下面是几点重要提示:
正确理解Rmd渲染输出、.bib文件状态和Zotero条目库的关系。简单说:a) Rmd的输出最终只会引用.bib文件里的文献条目。b)R引用包(rbbt)与Zotero可以实时联系(通过zotero-better-bibtex扩展插件),但是这并不意味着Rmd渲染输出也是与Zotero实时联系的。c).因此,在写作草稿阶段,可以暂时不用关心.bib,只需要保持与Zotero实时联系即可(完成实时搜索和插入条目)。但是在最后完稿之前,务必需要及时更新调整.bib文件(从Zotero 中导出文献为.bib文件,替换更新原来的.bib旧文件即可)。
Zotero中Citekey的设置是一个关键步骤,我们需要做出合理的权衡。这是因为一方面@nameYear的引用便捷性,要求每条文献的citekey必须要简单易用;但是另一方面,Zotero往往会管理海量的文献条目,从而又要求文献的citekey不能重复——不然就没办法精确引用文献了。不过Zotero考虑并提供了选择,可以用动态key(dynamic key),也可以用锁定key(pined key)。
因为文献条目中可能包含了abstract等长文本域,为了避免Zotero导出.bib后,R包citr识别报错的问题。最好把Zotero 软件的Better Bibtex(插件菜单)做出如下导出设定。
经验法则:中国知网有时候会文献条目抓取报错,这个时候很可能是你的网速或访问权限问题!
Zotero中有许多抓取中文学术网站的插件,但是大部分已经非常老旧,缺少及时的维护。
不过好在github上有一个Zotero translators中文维护小组(见GitHub repo)一直在致力于改善Zotero在中文知识资源抓取与管理上的用户体验。官方的使用说明非常清楚,操作也十分简单。一顿操作后,R用户生态下中文知识世界(Zotero小天地)也顿时变得安静许多了。
实际使用中发现,这个维护小组的更新频率还是比较高,为了随时保持最新的维护文件,可以使用git bash进行快速更新。具体技巧:
git bash,拷贝仓库到本地。$ cd d:/github-follow/translators_CN
$ git clone git@github.com:l0o0/translators_CN.gitgit命令直接拉取远程仓库$ cd d:/github-follow/translators_CN
$ git pull提示:可以尝试使用
git2r包进行git命名操作,但是win10系统下测试还无法实现。
require(git2r)
require(usethis)
# my credentials
cred <- git2r::cred_ssh_key(
publickey = "~/../.ssh/id_rsa.pub",
privatekey = "~/../.ssh/id_rsa"
)
# path of repository
path_repo <- "d:/github-follow/translators_CN"
# Open an existing repository
repo <- repository(path_repo)
branches(repo)
status(repo)
# pull but fail yet
git2r::pull(repo, credentials = cred)R命令拷贝目标文件到Zotero安装指定的位置:# renewed directory
my_folder <- "d:/github-follow/translators_CN/translators"
# target directory
tar_folder <- "d:/zotero-store/translators"
# copy and replace
require(R.utils)
R.utils::copyDirectory(
from = my_folder,
to = tar_folder,
overwrite = TRUE)notero是一款开源的zotero插件,可以在notion软件中实现对zotero文献库的数据库同步。
notero的几个具体安装步骤(参看):
下载最新的notero.xpi(release里面)
通过zotero插件界面(Tool \(\Rightarrow\) Add-on)安装notero.xpi
主要的配置过程及步骤如下(参看):
获取一个内部集成令牌
创建你想要同步Zotero项目的notion数据库。配置notion数据库的字节属性。需要注意数据库字节的正确设定(依照notero的官方说明)。
与您创建的集成共享数据库。最重要的是需要token、id。(zotero里要配置Notero插件,Notion里先要创建正确的数据库并邀请至Notero)
基于上述notion数据库,开始调用内部链接并进行引用和撰写笔记。(要点:对notion数据库文献条目右键copy link,然后去新笔记页面里paste,选择“mention page”)。
一些有用的视频教程如下:
Smart notetaking by starting with integrating Zotero and Notion: A first step (video) by Dr. Jingjing Lin
Sync Zotero to Notion to Level-Up Your Academic Research | AWESOME Notion Plug-In | Notion Tutorial (video) by Holly Jane Woods
3 frameworks into one — Write your next paper with R Studio!(see blog)
学习资源:
Making Professional RMD files (for PDF production) see blog
R包rticles (see github)
温馨提示:中文环境下,务必指定tynytex从国内镜像(如清华镜像)安装texlive包!(参看统计之都的讨论)
tinytex包的安装和维护(see yihui):
# install
install.packages('tinytex')
tinytex::install_tinytex()
tinytex::install_tinytex(repos = "https://mirrors.tuna.tsinghua.edu.cn/CTAN/systems/texlive/tlnet")
tinytex::uninstall_tinytex() # to uninstall TinyTeX
# maitain
library(tinytex)
tlmgr_search('/times.sty') # search for times.sty
tlmgr_install('psnfss') # install the psnfss package
tlmgr_update() # update everything如何编辑latex模板的博文。“Modifying R Markdown’s LaTeX styles”(链接)
R Markdown templates for Monash University see github
PengZhao开发的R包bookdownplus(github仓库pzhaonet/bookdownplus)配套的Latex[模板库站点] (https://bookdownplus.netlify.app/portfolio/)。
LaTeX Templates网站提供了一些模板下载(网址)
课程作业模板:
只有index.Rmd具有设置yaml信息的地位!
index.Rmd: This is the only Rmd document to contain a YAML frontmatter as described within Chapter 2, and is the first book chapter. —R Markdown: The Definitive Guide
_bookdown.yml设置new_session: true。# Example _bookdown.yml
book_filename: "bookdown_example"
delete_merged_file: true
new_session: true
language:
ui:
chapter_name: "Chapter ".Rmd文件在代码运行时都会强制使用new session,也即意味着各章的packages和data都相互独立。所以每一章的.Rmd文件最开始,需要分别设置options及加载packages_bookdown.yml的作用范围经验法则:
_bookdown.yml是存在作用范围的。它可以存放于项目的根目录下(root directory),作用于根目录下的.Rmd的输出,决定其输出样式。同时,它也可以存放于项目的子目录下(subdirectory),作用于改子目录下的.Rmd的输出,并决定其输出样式。
bookdown渲染(render),既可以完整而独立地输出一本书(book),也可以单独地输出一篇文档(document)。前者的结构和格式相对统一(书稿的统一格式),而后者则可以进行差异化的设置(不同文档可以有不同格式)。
因此,在使用_bookdown.yml进行输出格式设定时,首先需要确认自己的项目渲染方式:是一部书稿,或者仅是多种输出格式的文档?
(1)对于书稿型的项目,_bookdown.yml默认应该放在项目根目录下(root directory),其中的yaml参数设定,将会对根目录下的.Rmd文件产生作用,并决定其渲染输出的样式/格式。这也是bookdown包的默认项目形态。
(2)对于多样化文档型的项目,一般会用子目录(sub directory)的方式来管理和实现不同的文档输出。此时, _bookdown.yml应该放在各子目录下(sub directory),其中的yaml参数设定,将会分别对子目录下的.Rmd文件产生作用,并决定其渲染输出的样式/格式。这中项目形态也是我们常见的情形之一。需要注意的是此时,根目录下的_bookdown.yml,不会对子目录下的.Rmd产生作用。具体可参看队长问答1以及队长问答2。
levelName
1 course-stat
2 ¦--_bookdown.yml
3 ¦--course-stat.Rproj
4 ¦--bib
5 ¦--public
6 ¦--01-class-instruction
7 ¦ ¦--demo01.Rmd
8 ¦ °--demo02.Rmd
9 ¦--02-class-slide
10 ¦ ¦--slide01.Rmd
11 ¦ °--slide02.Rmd
12 °--03-lab-exercise
13 ¦--lab01.Rmd
14 ¦--lab02.Rmd
15 °--lab03.Rmd 根目录下_bookdown.yml的设定如下(不会对子目录下的.Rmd产生作用):
book_filename: bookdown
clean: [packages.bib, bookdown.bbl]
#rmd_files: ["02-lab-exercise/lab00-research-training.Rmd"]
rmd_subdir: true
#new_session: yes
language:
label:
fig: "图"
tab: "表"
def: "定义 "
thm: "定理 "
prp: "假设 "
proof: "证明 "
ui:
edit: "编辑"
chapter_name: ["第 ", " 章"]此时需要给各个子目录设定不同的_bookdown.yml参数,从而使其对子目录下的.Rmd产生作用:
path_sub <- c(
path,
"course-stat/03-lab-exercise/_bookdown.yml",
"course-stat/02-class-slide/_bookdown.yml" )
mytree_sub <- data.tree::as.Node(data.frame(pathString = path_sub))
print(mytree_sub) levelName
1 course-stat
2 ¦--_bookdown.yml
3 ¦--course-stat.Rproj
4 ¦--bib
5 ¦--public
6 ¦--01-class-instruction
7 ¦ ¦--demo01.Rmd
8 ¦ °--demo02.Rmd
9 ¦--02-class-slide
10 ¦ ¦--slide01.Rmd
11 ¦ ¦--slide02.Rmd
12 ¦ °--_bookdown.yml
13 °--03-lab-exercise
14 ¦--lab01.Rmd
15 ¦--lab02.Rmd
16 ¦--lab03.Rmd
17 °--_bookdown.yml 经验法则:要么按book down进行渲染,要么单独文件渲染,可谓“鱼与熊掌不可兼得”。如果要单独输出某一个Rmd文档为目标类型(如bookodwn::word_document2),则需要先把
_output.yml文件进行屏蔽,例如修改为_Xoutput.yml。如果要渲染为book,则需要再将它改回来!
Rmarkdown说明文档中,指出可以通过在yaml区域进行设定,以定制化knit按钮,渲染输出自己希望的类型。
knit: (function(input, ...) {rmarkdown::render(input)})尽管如此,在bookdown包的设定下,目前还没有找到一个全局参数,来修改knit按钮的默认行为。
只要是_output.yml文件存在,则knit: (function(input, ...) {rmarkdown::render(input)}),一直会输出html结果,而不是指定的目标结果(如word)。
参考资料:
options(blogdown.knit.serve_site=FALSE)?Bookdown说明书2.2.2 Theorems and proofs
定理环境(theorem environment)下的block类型有:
theorem
lemma
corollary
proposition
conjecture
definition
example
exercise
证明环境(proof environments)下目前支持的block类型包括:
proof
remark
solution
Bookdown说明书里指出了个性化blocks2.7 Custom blocks
如果是html输出,则需要去设置。bookdown内置的block类型包括:
rmdcomment
rmdlist
rmdnotes
也可以参考yihuixie的案例CSS
{theorem,BLUE,name="高斯-马尔可夫定理(Gauss-Markov Theorem)",echo=TRUE}
在正态经典线性回归模型假设(N-CLRM)下,采用普通最小二乘法(OLS),得到的估计量$\hat{\beta}$,是真实参数$\beta$最优的、线性的、无偏估计量(BLUE)。记为:
\xrightarrow[\text{N-CLRM}]{\text{OLS}}\hat{\beta} \xrightarrow[\text{}]{\text{BLUE}} \beta所有类型的block都需要给出echo=TRUE的参数设置才能正常显示
html输出和latex输出的block类型支持是不一样的,前者应该更多
表格排版还是需要kable和kableExtra的结合。kableExtra的latex参数请参看Zhuhao的awesome_table_in_pdf。
zhuhao提到了kableExtra如何实现多形式输出的办法
需要注意的是环境参数设置的变化。一种情形是,在Rstudio中点击knitr(或biuld),都会自动识别knitr.table.format =是latex环境还是html环境。另一种情形就是在console中手动运行比如render_或preview_chapter(),这时就需要手动写入执行环境是latex或html。
自动配置情形下,可以全局设置options(knitr.table.format = "latex")。如果不想自动配置,则可以禁用它options(kableExtra.auto_format = FALSE)。
手动配置情形下,则需要在code chunk里对kable()函数设定format="latex"。
函数kable()处理的数据类型应该是dataframe(或tibble)。不然booktab=T或kable_styling(latex_options = c("striped"))将会不起作用。请参看在线问答R markdown KableExtra latex table booktabs not working
调用latex包的先后顺序很有影响。例如涉及到颜色的使用,可能出现报错Option clash for package xcolor。这个时候latex包的先后顺序会带来各种问题。参看在线问答Option clash for package xcolor
(https://stackoverflow.com/questions/16507191/automatically-adjust-latex-table-width-to-fit-pdf-using-knitr-and-rstudio)
有时候我们会独立地展示图片(.png之类),有时候我们还希望在表格中展示图片(.png之类)或图标(icon之类)。
如下R代码块(R code chunk)情况下,是可以正确输出html,但是却无法正确输出Latex:
动图是不行的。knitr::include_graphics('local.gif')
在线图片是不行的。knitr::include_graphics('https://commonmark.org/images/markdown-mark.png')
此外,在kable环境下,data.frame中出现如下value,也是可以正确输出html,但是却无法正确输出Latex:
Rmarkdown语言,
HTML语言,<image source="picture/object/Alpha,png">
yihuixie指出了这种混合表格是不能兼得两种输出,同时也为latex输出指明了出路——使用//includgraphics。然而此//includgraphics并非彼include_graphics()。
错误的include_graphics()。我开始一直认为是使用R code chunk下的include_graphics()函数。当然是无功而返,无论怎么做都无法实现正确的latex输出。
正确的//includgraphics。进一步googlew问答add and resize a local image to a .Rmd file in RStudio that will produce a pdf,终于明白了其中玄机。原来yihuixie所说的//includgraphics是一种原生的latex语法。——略加调整,问题果真迎刃而解!
使用latex语法正确处理data.frame的单元格value(此处为字符串):"\\includegraphics{picture/object/Alpha.png}"。如果需要调整图片属性(如大小),则可以处理data.frame的单元格value为:"\\includegraphics[width=0.9\linewidth]{picture/object/Alpha.png}"
设置kable参数:kable(dat, escape = FALSE,booktab=T)。(假定环境配置为自动判别latex还是html输出,此处为latex输出)
if函数上场,实现latex和html并行输出。根据输出格式(output)来设定data.frame的value值。而且再knitr1.18版本开始,可以直接使用两个函数来自动判明输出格式:
knitr::is_html_output()
knitr::is_latex_output()如果latex表格很长,一般需要调用longtable参数,但是kableExtra()函数下自动缩放大小latex_options = c( "scale_down")就会失效。并提示:Longtable cannot be resized。但是可以利用kableextra的函数column_sep()来设定各列的宽度。
```{r}
kable_styling(full_width = F,
latex_options = c( "scale_down","striped")) %>%
column_spec(5, width = "15em")
```表格中显示图标(icon)。则可以参看add a fontawesome icon to a table in Rmarkdown
建议尽量对整个单元格进行latex参数操作。
单元格部分字符加粗,则必须使用latex语法:
```{r}
dat <- data.frame(
country = c('Canada', 'United Kindom'),
abbr = c("Alpha","Coef"),
var1 = c(1, 2),
var2 = rnorm(2),
var3 =c("\\textbf{加粗}","*斜体*")
)
```kable如何显示数学公式。
数学公式可以参看在线问答math in table-header not working
报错信息:没有章标题编号,且第一章是以0.1 xxx这样的错误初始编号开始。
解决办法:可以参看:问答贴”Creating unnumbered chapters/sections”(见链接)
在chapter-01-intro.Rmd的开头要设定LaTex语法\mainmatter表明这是书稿的主体部分。
同时需要在_output.yml里要设定padoc的参数pandoc_args: --top-level-division=chapter。具体如下:
bookdown::pdf_book:
includes:
in_header: latex/preamble.tex
before_body: latex/before_body.tex
after_body: latex/after_body.tex
keep_tex: true
dev: "cairo_pdf"
latex_engine: xelatex
citation_package: natbib
template: latex/template.tex
pandoc_args: --top-level-division=chapter不要在R code chunk的options中出现特殊字符。比如:fig.cap=中出现了特殊符号&,则会报错。
fig.cap="绘制Line & Symbol图"图题中的数学公式符号,使用货币符号表达是需要注意LaTeX的规范写法(特定命令符需要加双斜杠\\alpha)。例如:fig.cap="判定系数$R^2$和调整判定系数$\bar{R}^2$",则LaTex会报错! Text line contains an invalid character.。正确的写法应该是(参看解决方案):
fig.cap="判定系数$R^2$和调整判定系数$\\bar{R}^2$"正文内容中列表(list)层级太多,则会报错:LaTeX Error: Too deeply nested.。如果非要那么多层级,就需要加载LaTex的enumitem package(让tinytex自动加载去吧),并在preamble.tex中调用它(参看在线文达jgm的 解决方案):
\usepackage{enumitem}
\setlistdepth{9}
\setlist[itemize,1]{label=$\bullet$}
\setlist[itemize,2]{label=$\bullet$}
\setlist[itemize,3]{label=$\bullet$}
\setlist[itemize,4]{label=$\bullet$}
\setlist[itemize,5]{label=$\bullet$}
\setlist[itemize,6]{label=$\bullet$}
\setlist[itemize,7]{label=$\bullet$}
\setlist[itemize,8]{label=$\bullet$}
\setlist[itemize,9]{label=$\bullet$}
\renewlist{itemize}{itemize}{9}
\setlist[enumerate,1]{label=$\arabic*.$}
\setlist[enumerate,2]{label=$\alph*.$}
\setlist[enumerate,3]{label=$\roman*.$}
\setlist[enumerate,4]{label=$\arabic*.$}
\setlist[enumerate,5]{label=$\alpha*$}
\setlist[enumerate,6]{label=$\roman*.$}
\setlist[enumerate,7]{label=$\arabic*.$}
\setlist[enumerate,8]{label=$\alph*.$}
\setlist[enumerate,9]{label=$\roman*.$}
\renewlist{enumerate}{enumerate}{9}段落首行缩进。在preamble.tex中条用如下包[解决方案(https://stackoverflow.com/questions/29460112/first-line-paragraph-indenting-in-pdfs-using-r-markdown)]
% first-line paragraph indenting
\usepackage{indentfirst}
\setlength\parindent{24pt}页边距调整。需要在output.yaml文件中进行设置(参看解决方案)
geometry: [a4paper, tmargin=2.5cm, bmargin=2.5cm, lmargin=2.5cm, rmargin=2.5cm]
正确设置章序号。如果修改了documentclass:,那么就需要告诉Pandoc你是按chapter来编码的,而不是section(默认)。在output.yaml文件下设置pandoc_args: --top-level-division=chapter。(参看解决方案)
documentclass: ctexbook
bookdown::pdf_book:
includes:
in_header: latex/preamble.tex
before_body: latex/before_body.tex
after_body: latex/after_body.tex
keep_tex: yes
dev: "cairo_pdf"
latex_engine: xelatex
citation_package: natbib
template: latex/template.tex
pandoc_args: "--top-level-division=chapter"
toc_depth: 4
toc_unnumbered: no
toc_appendix: yes
quote_footer: ["\\begin{flushright}", "\\end{flushright}"]正确处理页码序号。其实bookdown电子书 6.3 Publishers专门提到了这一点,只是我一直没有细看。另外也可以参看在线问答Page Numbering in R Bookdown。 总体意思就是要让Pandoc知道哪些部分属于\frontmatter,\mainmatter,\backmatter。所以需要做如下几件事情:
在preamble.tex文件下加入代码行
\frontmatter
在before_body.tex文件下加入代码行
\frontmatter
在(序言)
index.Rmd文件第一行加入代码行\frontmatter
在(第一章)
01-introduction.Rmd文件第一行加入代码行\mainmatter
在after_body.tex文件下加入代码行
\backmatter
总之,这些标记代码可以插入到相应的章节,合适的位置。跟word的分节符很像。
! File ended while scanning use of \@writefile.。突然之间,Latex无法编译,反复查看yaml代码,感觉都没有问题,大半个下午解决不了(包括更新bookdown和Rstudio;多次重启。)。google搜索,最后采用了David Carlisle的建议,把.aux等日志文件删除,重新Latex编译,最后消除了不能编译的错误。——最终还是没有明白原因。需要设定的地方包括:
保存文献列表文件,例如bib/econometrics.bib文件(可以通过Zotero进行自动关联更新文献列表)。
在bookdown工作项目下,设定第一个Rmd文件(一般为index.Rmd)的yaml区域信息,具体如下(见bookdown官方说明):
# set following in index.Rmd file
bibliography: [bib/bib.bib, bib/econometrics.bib]
biblio-style: apalike
link-citations: yes
csl: 'chinese-gb7714-2005-author-date.csl'需要注意的是,只有在pdf输出时,优雅漂亮的参考文献列表样式才可以做出更多设定和使用。例如biblio-style: apalike才能生效。
此外,对于参考文献列表,如果要放置在指定位置,则需要用到如下的html标记语言(见bookdown 官方说明):
# 参考文献{#sec-reference}
<div id="refs"></div>如下设置,可以实现侧边栏章节导航目录的折叠/展开效果,以及当前标题高亮。(see bookdown website)
# set following in your `_output.yml` file
bookdown::gitbook:
config:
toc:
collapse: section # or option "subsection"
scroll_highlight: true经验法则:- 最好是等整个root/A.Rmd文档的中文标题都编写妥当后,再统一进行中文标题批量拼音化标签处理。 - 尽量保持原”root/A.Rmd”文档,并复制一份到”root/py/A.Rmd”。中文标题批量拼音化标签处理只会添加label给后者(如”# 中文标题heading {#sec-zwbtheading}“),确认后者没有问题后,再覆盖替换”root/A.Rmd”文档。
此外,bookdownplus包(见使用介绍)据说也提供了不少扩展支持,比如中文友好、中文标题自动拼音化标签(需要使用辅助包pinyin::bookdown2py(),见github repo),但是实际使用起来还是感觉十分凌乱,文档说明编写也比较马虎。
```{r}
#|eval: false
# devtools::install_github("pzhaonet/pinyin")
require(pinyin)
# 导入字典环境
mypinyin <-pydic(method = "toneless",only_first_letter = T, dic = "pinyin2")
# 将文件夹py/内的.rmd文件的标题进行拼音转换,它会自动备份到backup/文件夹下。
bookdown2py(folder = "py", dic = mypinyin,remove_curly_bracket = T,other_replace = NULL)
```需要注意的地方:
中文标题批量拼音化标签处理,会涉及到三个文件夹的关系:一是原来书章的”root/A.Rmd”文档(有中文标题,但是没有引用标签),后面操作完后它应该要被手动替换。二是暂存的书章文档”root/py/A.Rmd”,主要用于中间的确认和修改(确保生成的标题引用标签符合你的要求),如果确认无误,就可以替换前述”root/A.Rmd”;三是备份文件”root/backup/A.Rmd”,该文件夹会自动生成,按照字面理解应该是为了做万无一失的备份。.gitignore文件里也可以设为忽略文件夹(保留在本地,但不上传到github)。
对于bookdown的多章节.Rmd,其中一章”root/A.Rmd”的一级标题heading1的标签label(如”# 中文标题heading {#sec-zwbtheading}“),将会作为该章输出的文件名,出现在”root/_book/zwbtheading.html”。如果你要指定html输出的文件名,那么就需要额外手动修改该一级标题的标签label(如修改为”# 中文标题heading {#sec-first-chapter-intro}“)。因该对pinyin::bookdown2py()进行改进,允许已经设定好引用标签的,就不再自动生成,例如添加一条参数,如replace.exist = FALSE。
每次运行pinyin::bookdown2py()默认都会在中文标题后留下1个空格,然后才添加引用标签, 例如”# 中文标题heading {#sec-zwbtheading}“。有时候书章的标题会边写边增减或调整,那么就需要连续多次运行pinyin::bookdown2py()来生成新标题的引用标签。为了不影响已经生成的标题引用标签,而只是单纯生成新标题的引用标签,那么运行前就先要批量把这个预留的空格去掉。具体方法就是批量将“ {#sec-”替换为“{#sec-”。如果不这么处理,那么每次运行pinyin::bookdown2py()就都会将空格转换为下划线”_“,十分难看。
经验法则:(1)要采用稳健而可靠的word渲染机制。
bookdown::word_document2()远比officedown::rword_document()要可靠。(2)目标实现与细节完善,前者要放到更重要的地位上。bookdown::word_document2()放弃了更多对word style的细节直接操作,但是编写工作更简单。officedown::rword_document()强调直接对word style的全面控制,细节会好,但是却要重新学习使用一套语法规则,使用难度和成本过高,会影响书稿内容的编写进度。(3)实际上最求word输出的一些细节,如图表目录、交叉引用的链接跟踪等,并没有你想象中的那么重要。
从出版商编辑的角度来看,实际上可接受的书稿文档也就是有两种:一是MS word(输出格式为.docx),国内出版社普遍以此为基本书稿格式;二是LaTex(输出格式为.pdf),版式严谨且漂亮,但国内出版社极少采用此书稿格式。
从书稿编写者的角度来看,可供选择的写作工具集其实也并没有想象的那么多。虽然已经有非常不错的完整书稿编写支持包bookdown,只是它对html和pdf支持比较好,但是对word则有诸多不支持的地方。yihui大神一直认为基于html的输出格式才是未来趋势,对于传统的LaTex pdf输出一直耿耿于怀,这才开发出R包bookdown,就更不要提MS word的输出格式了。所谓“一套代码脚本,同时输出多种格式文档”,本质上只是一厢情愿的自嗨。因为三种格式的输出完全就是不同的逻辑“路线”,自然是强扭的瓜不甜了。
Although Latex is capable of some very fancy formatting, it is notoriously complicated. You can easily get sucked into a blackhole of googling for obscure Latex code or packages to make minor adjustments to the appearance of your PDF. (see blog A better way to go to Word from Rmd)
bookdown::docx_document2(见 bookdown官方Chapter 8 Word)、尝试word修订批注可回传给Rmd的redoc包(2020年后基本停止维护,见github repo “noamross/redoc”)、以及其他重要office生态包如:officer、officedown、flextable、mschart和rvg等。总结起来,作为书稿手稿写作,需要明确自己的需求:
输出word,基本的模板样式已经够用。
成稿方式:分章写,最后合并。
必须要的:公式自动编号;交叉引用;参考文献;自动导出源图;支持预览(html)。
暂不需要:图表目录;页面分列。
目前word输出需要解决的问题清单如下(动态增加或调整):
相关资料:
bookdown官方Chapter 8 Word
office生态officeverse
需求描述:考虑到书稿章数较多,每次都”build book”会导致”_book/your-book-name.docx”文档非常大。因此,希望使用预览函数bookdown::preview_chapter("chpt-05.Rmd"),仅得到指定章的word输出文档。
问题描述:以上操作可以得到指定章节的word预览文档。但是有如下问题。
(3)解决办法:暂时没有解决。
基本操作是,首先需要在”chpt-05.Rmd”的yaml区域设置site和output参数;然后再使用bookdown::preview_chapter("chpt-05.Rmd")。
site: "bookdown::bookdown_site"
output:
bookdown::word_document2:
fig_caption: true
#reference_docx: template/create-template-tiny.docx# (APPENDIX) 附录 {-}
# 附录A:{#sec-Appendix-A}
This will be Appendix A.(1)问题描述:
同时设置图题和表题样式(如下),则会报错。
language:
label:
fig: !expr function(x) sprintf("图%s ", x)
tab: !expr function(.x) sprintf("表%s ", .x)只设置表题样式(如下),也会报错。
language:
label:
fig: "图 "
tab: !expr function(.x) sprintf("表%s ", .x)报错信息:
Exited with status -1073740940.此外:
Rmarkdown语法如加粗语法** text **对word输出不会对图题或表题样式产生作用。
公式标签默认为数字形式(如(1.2)),而不会不显示复合标签样式(如(式1.2))。
(2)解决办法:
对于数学公式比较多的书稿,公式的呈现和交叉引用显得特别重要。目前都没有看到在word输出格式上的有效解决方法。这普遍被认为是pandoc的问题(相关讨论,可参看网络问答1),或者说MS word本身的开放性支持不足。也就是说Rmarkdown对其也是无能为力的,哪怕是bookdown包对word支持做了很好的优化,也没有把这个问题解决(参看rmarkdown官方解释(see webpage):“Equation references work best for LaTeX/PDF output, and they are not well supported in Word output or e-books.”)。
至于在rmarkdown或bookdown之上构建的其他word支持包,如officer或者officedown则更加鞭长莫及了。也有一些“偏门”一点的解决方案,例如equatags包(见github repo)就尝试把公式转换为图片插入到word里去——不过还是没有解决交叉引用这一根本性问题。
重要发现:根据bookdown的问题区提问Equation numbering in docx should be improved and shown as PDF/LaTeX,bookdown的共同开发人cderv似乎已经解决了word输出(bookdown::word_document2())下的这个问题。
如下代码,将产生如下效果:
## math
参考公式\@ref(eq:test)
\begin{equation}
TSS=ESS+RSS (\#eq:test)
\end{equation}
Below is the binom equation
\begin{equation}
f\left(k\right)=\binom{n}{k}p^k\left(1-p\right)^{n-k} (\#eq:binom2)
\end{equation}最终输出效果如下(见图@ref(fig:word-bookdown)):
knitr::include_graphics("pic/bookdown-word-equation.png")
提示:
word输出格式bookdown::word_document2()下,latex公式不需要使用“双货币符号”($$)来开始和结束。同时,公式代码的每一行结尾不能有空格!
在word输出格式officedown::rdocx_document()的下,默认采用base_format = "rmarkdown::word_document",此时公式自动编号会失效(见图@ref(fig:word-rmarkdown))。
knitr::include_graphics("pic/officedown-word-math-fail.png")
进一步地,考虑到officedown::rdocx_document()的默认模板是base_format = "rmarkdown::word_document",此时word输出的公式序号是公认不能正确显示的。好在还可以调整为bookdown下的基本格式:base_format = "bookdown::word_document2",从而可以实现word输出下,公式序号的正常显示。
总结起来,要实现word下公式自动编号,需要考虑到R/word生态下几个R包的递进演化关系:rmarkdown::word_document()是最早基于pandoc流程来支持word输出的;为了改进自动编号和交叉索引,yihui开发出了bookdown::word_document2()来进一步强化word支持;再后来officedown::rdocx_document()进一步基于officer包支持了多种word样式(分列、页面布局等),只是其默认格式是基于base_format = "rmarkdown::word_document()",如果需要公式自动编号和交叉引用,就需要设定基本格式为officedown::rdocx_document(base_format = "bookdown::word_document2")。
如果直接在_output.yaml文件中设定MS word输出bookdown::docx_document2,往往会出现如下报错:
Error: Functions that produce HTML output found in document targeting docx output.
Please change the output type of this document to HTML. Alternatively, you can allow
HTML output in non-HTML formats by adding this option to the YAML front-matter of
your rmarkdown file:
always_allow_html: true
Note however that the HTML output will not be visible in non-HTML formats.
Execution halted
Exited with status 1.显然是因为.Rmd文件中有部分代码块code chunk不支持MS word输出。有大神指出可以设定htmlwidget的默认行为,例如设定knitr的默认参数(option)为screenshot.force = knitr::pandoc_to("docx")。这样就可以将DT::datatable()之类不支持word输出的,转换为图片格式,从而可输出到word格式。
解决办法:
此时,不能使用DT::datatable()参数下的caption = "your fig caption", 而是应该在chunk 参数下设置:fig.cap= "your fig caption"。
这是使用DT和webshot得到的htmlwidget类型表格的截图,效果见图@ref(fig:mtcarsDT)。
``'`{r mtcarsDT, screenshot.opts = list(selector = ".dataTables_wrapper"), fig.cap="mtcars dataset with DT and webshot",echo=TRUE}
DT::datatable(mtcars,
#caption = "家庭收入与支出案例数据",
options = list(
dom ="tip",
pageLength = "10"
))
``'````{r, screenshot.opts = list(selector = ".dataTables_wrapper")}
#| label: fig-mtcarsDT
#| fig-cap: "mtcars dataset with DT and webshot"
DT::datatable(mtcars,
#caption = "家庭收入与支出案例数据",
options = list(
dom ="tip",
pageLength = "10"
))
```具体可参看:
可以参看yihui 在bookdown中的官方说明:HTML widgets
问题症状:bookdown::word_document2()输出时,knitr::kable(mtcars)的编译表格会出现错乱,表格不复存在,表格行会变成文本段落行。
解决思路:google放狗,“队长问答”指出是kableExtra包默认设定带来的问题。可以参看haozhu的github问题讨论:kable output to word fails in 0.9.0 when kableExtra is attached。以及“队长问答”讨论:Why is my knitr::kable table not displayed after knitting to word?
```{r}
library('kable')
library('kableExtra')
```处理办法:全局设定options(kableExtra.auto_format = FALSE),顺利解决问题!
经验法则:word输出下的标题换行,需要用到空格(2中文空格符或4英文空格符)+
\n。空格数量很关键!
yaml区域的设置具体可参看如下:
title: "教育部产学研合作协同育人项目 \n湖南智擎科技有限公司"
subtitle: "计量经济学开源实践教学及R语言实现"
author: "胡华平"
output:
bookdown::word_document2:
fig_caption: yes
toc: no
toc_depth: 4
number_sections: true
global_numbering: true两种办法:
html语言。如背景色<span style="background:red;"> my test</span>的效果为: my test。字体颜色<span style="color:red;"> my test</span>的效果为: my test。
R函数。参看yihui文档Using an R function to write raw HTML or LaTeX code。
colorize <- function(x, color) {
if (knitr::is_latex_output()) {
sprintf("\\textcolor{%s}{%s}", color, x)
} else if (knitr::is_html_output()) {
sprintf("<span style='color: %s;'>%s</span>", color,
x)
} else x
}具体使用方法为colorize("some words in red", "red"),实际效果为:some words in red。
学习资源:
R包工具:
R/exams包。exams: Automatic Generation of Exams in R(见cran;以及官网)。
R-forge官方问答区。很多问题可能并不是R相关的话题,例如在线平台等;此外一些提到的问题,可复现性也不强。
关心的问题:
能否支持中文?
能否支持多种输出格式(docx)?
支持哪些题型类型?(计算题)
是否支持章节知识点分布?(权重)
阅卷评分是否能自动化?
题型支持(见官方文档:Dynamic Exercises):
Single correct answer MCQ (schoice)
Multiple correct answer MCQ (mchoice)
Numeric answer (num)
String (string)。填空题,需要严格一致的字符回答。
Cloze (Combinations of the Above)
word格式输出使用函数exams2pandoc()(见函数说明),只是模板的格式选择里没有template.docx。显然,作者更倾向于使用Latex模板。作者申明了他的理由: “Using LaTeX in R/exams: What, Why, How?”(博文链接)。
```{r}
#install.packages("exams")
require(exams)
# Automatic generation of exams via pandoc, by default in docx format.
exams2pandoc()
```exams2pandoc()函数参数template的使用说明如下:
template character. A specification of a template in either LaTeX, HTML, or Markdown
format. The default is to use the "plain.tex" file provided but an alternative
"plain.html" is also available.当然,默认模板plain.tex是可以修改的,作者在包说明里并没有详细写明,这一点作者在堆栈问答做出了解释(链接:exams2pandoc error message - invalid template )。
参数化报告主要有两种情形:
(范围)读者不同。数据一样,代码调整。SCOPED: a report made with a single source, but with different variants scoped for different audiences.
(筛选)内容不同。数据变化,代码不变。CHANGE: code; KEEP: data
两种参数化渲染方式:输出单份报告;或者输出批量报告。
事实上,参数与自动化报告的交互关系有两种:一是参数自上而下影响报告代码内容(常见操作);二是参数也可以通过自下而上的方式影响yaml参数、输出文件名(output file name),以及文档元信息(document’s metadata)。
具体实现操作:
(1)动态yaml。在yaml区域(YAML fields)使用参数实现动态的yaml设定(dynamic YAML)。
Use params inside rmarkdown::render → dynamic render
(2)动态render。在rmarkdown::render()使用参数,可以定制成.R执行函数文件(参考_render_single.R)。
(3)动态params。使用参数来控制参数!
(4)动态metadata。使用参数来动态控制yaml区域设定!
一个操作实例:
```{r}
purrr::walk(
.x = list(send_to = list(first = "Sophie", last = "Faldo")),
~ rmarkdown::render(
input = "index.Rmd",
output_file = glue::glue("valentine-for-{.x$first}.html"),
output_options = list(theme = "journal"),
params = list(send_to = {.x})
)
)
```注意事项:
(1)封装函数文件_render.R务必保持如下形式:
```{r}
function(input, ...) {
...
rmarkdown::render(
input = input
)
}
```(2)传递参数给yaml务必需要如下形式(必须以$value结尾):
# set encoding for CJK language
knit: source('_render.R', encoding ='UTF-8')$valuea.如果出现中文字符乱码,则应该设定文档编码格式
encoding ='UTF-8'。
b.如果文件路径有层次结构,则应使用
here包,如here::here("02-lab-exercise","_render.R")。
一些参考资料:
在your.Rmd文件的yaml区域设置如下:
knit: (function(inputFile, encoding) {
outFile <- sub(pattern = "(.*)\\..*$", replacement = "\\1", basename(inputFile));
out_dir <- 'public';
rmarkdown::render(inputFile,
encoding=encoding,
output_file=file.path(dirname(inputFile), out_dir, outFile)) })脚注列表与文献列表的位置关系,前者总是在文档最后,并且原生有一道横线。↩︎